基于ChatGLM3-6B+Lora构建基本法律常识大模型
原创2025/3/1...大约 4 分钟
1. 如何增强模型能力?
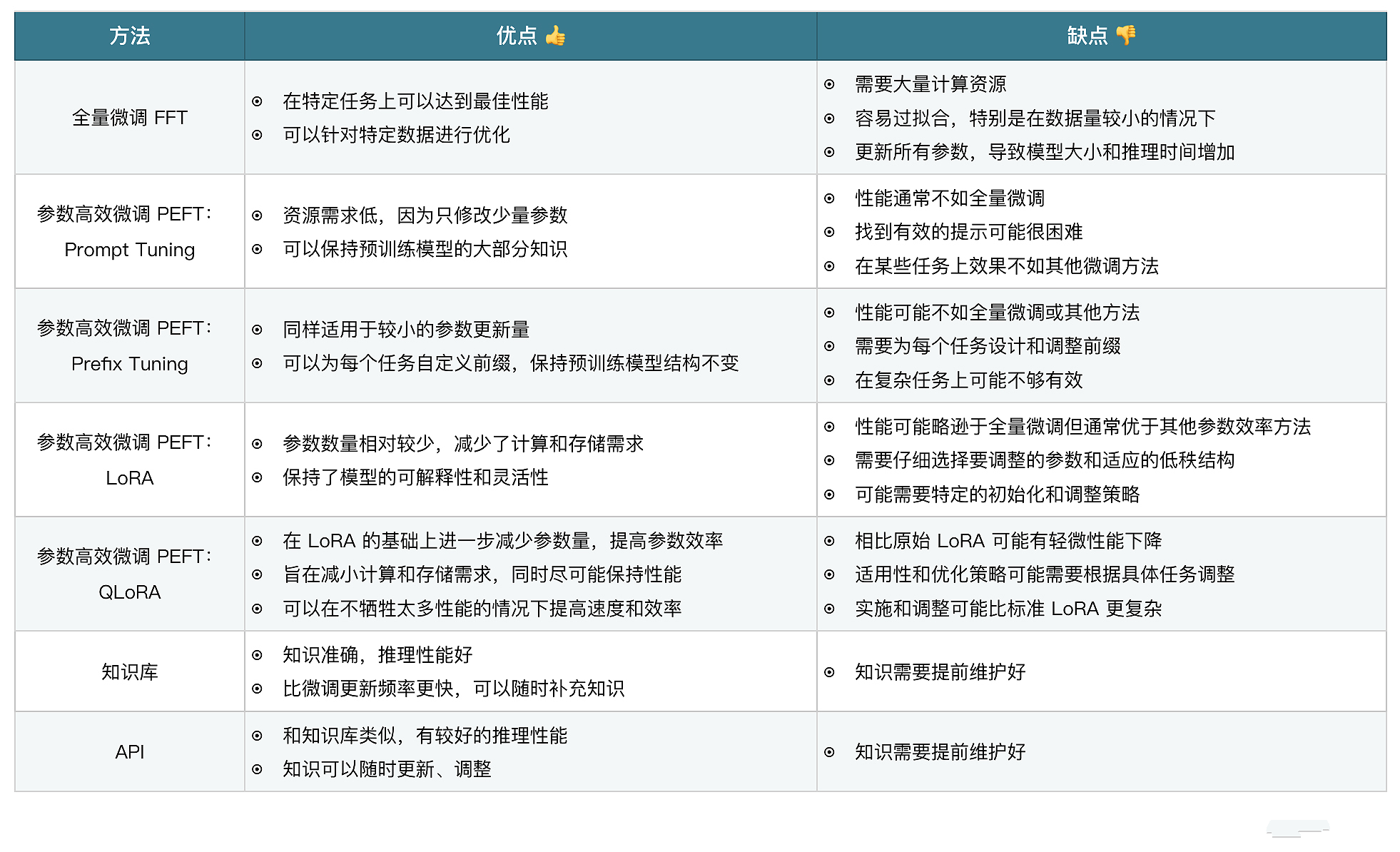
微调是其中的一个方法,当然还有其他方式,比如外挂知识库或者通过 Agent 调用其他 API 数据源,下面我们详细介绍下这几种方式的区别。
- 微调是一种让预先训练好的模型适应特定任务或数据集的方案,成本相对较低,这种情况下,模型会学习训练者提供的微调数据,并且具备一定的理解能力。
- 知识库使用向量数据库或者其他数据库存储数据,为大语言模型提供信息来源外挂。
- API 和知识库类似,为大语言模型提供信息来源外挂。
简单理解,微调相当于让大模型去学习一门新的学科,在回答的时候进行闭卷考试,知识库和 API 相当于为大模型提供了新学科的课本,回答的时候进行开卷考试。几种模式并不冲突,我们可以同时使用几种方案来优化模型,提升内容输出能力,下面我简单介绍下几种模式的优缺点。
注意,大模型领域所谓的性能,英文原词是 Performance,指推理效果,并非我们软件开发里所说的接口性能,比如响应时间、吞吐量等。
了解这几种模型的区别,有助于我们进行技术方案选型。在大模型实际落地过程中,我们需要先分析需求,然后确定落地方式。
- 微调:准备数据、微调、验证、提供服务。
- 知识库:准备数据、构建向量库、构建智能体、提供服务。
- API:准备数据、开发接口、构建智能体、提供服务。
接下来我会通过一个真实的案例,把整个过程串起来。
2. 企业真实案例
在 ChatGPT 火爆以后,很多公司都在想办法将 AI 大模型引入日常工作中,一方面嵌入到产品中,提升产品的竞争力;一方面引入到企业内部,提升员工工作效率。就拿企业内部助手来说,它有很多使用场景,比如文案生成、PPT 写作、生活常识等等。这里我们举一个法律小助手的例子。一般来说,当我们确定场景后,首先进行的就是需求分析,因为有些场景不一定是 AI 场景,有些是 AI 场景,但是可能可以通过小模型解决,所以我们在实际需求落地的过程中,一定要先进行完整的需求分析。
2.1 需求分析
法律小助手用来帮助员工解决日常生活中遇到的法律问题,以问答的方式进行,这种场景可以使用知识库模式,也可以使用微调模式。
- 使用知识库模式的话,需要将数据集拆分成一条一条的知识,先放到向量库,然后通过 Agent 从向量库检索,再输入给大模型,这种方式的好处是万一我们发现数据集不足,可以随时补充,即时生效。
- 还有一种方式就是进行微调,因为法律知识有的时候需要一定的逻辑能力,不是纯文本检索,而微调就是这样的,通过在一定量的数据集上的训练,增加大模型法律相关的常识及思维,从而进行推理。经过分析,我们确定下来,使用微调的方式进行。接下来就是准备数据了。
2.2 准备数据
把csv格式的文件下载下来之后还需要转换成我们可用的json格式
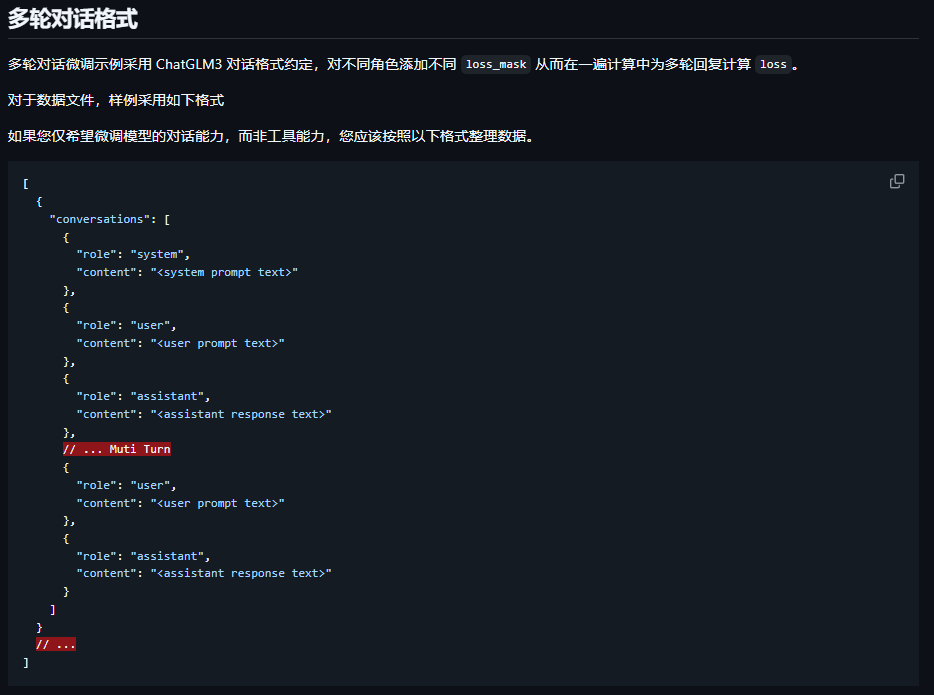
示例代码:
import csv
import json
with open('lawzhidao_filter.csv',mode='r',encoding='utf-8')as c,open('a.json',mode='w',encoding='utf-8')as j:
csv_r=csv.DictReader(c)
for row in csv_r:
title=row['title']
reply=row['reply']
conversation={
'conversations':[
{'role':'user','content':title},
{'role':'assistant','conten':reply}
]
}
js_line=json.dumps(conversation,ensure_ascii=False)
j.write(js_line+'\n')通过上面的代码,我们就可以成功将下载下来的 CSV 格式的数据集,格式化成微调所需的数据集。接下来就可以准备微调了。