01-ollama 的安装与基础应用
1. Windows GPU 驱动全套配置
1.1 安装 NVIDIA 驱动
1.1.1 📋 确认硬件条件
检查你的显卡:
- 必须是 NVIDIA 显卡才能用 CUDA 加速。
- 推荐显存:至少 6GB,更高更好。
- 桌面版、笔记本版显卡都可以,比如 RTX 3060、3080、4090。
👉 打开命令行,输入:
nvidia-smi如果能看到显卡型号和驱动版本,说明 NVIDIA 驱动已安装;否则继续下面的步骤。
1.1.2 🖥 确认电脑显卡
1.1.2.1 🖥 Windows 系统
方法一:使用设备管理器
按下
Win + X,选择 设备管理器。展开 显示适配器,就能看到当前电脑安装的显卡型号。
方法二:使用任务管理器
按下
Ctrl + Shift + Esc打开任务管理器。点击 性能 选项卡。
左侧可以看到 GPU 0、GPU 1 等,点击可以查看详细显卡信息。
方法三:使用 dxdiag 工具
按
Win + R打开运行窗口。输入
dxdiag,回车。在弹出的 DirectX 诊断工具中,切换到 显示 页签,可以看到显卡名称和显存信息。
方法三:使用命令行(更高级)
按下
Win + R,输入:wmic path win32_VideoController get name这个命令会列出你所有显卡的名称。
运行后输出如下:
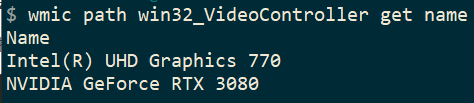
image-20250511143257046
1.1.2.2 🍎 macOS 系统
方法:使用系统信息
点击屏幕左上角的苹果标志 。
选择 关于本机。
在弹出窗口中,点击 更多信息…。
在左侧列表中,找到 图形/显示器,就能看到显卡型号、显存大小等信息。
1.1.2.3 🐧 Linux 系统
方法一:使用命令行 在终端执行:
lspci | grep -i vga会显示类似下面的信息,比如:
00:02.0 VGA compatible controller: Intel Corporation UHD Graphics 630 (Mobile)
01:00.0 3D controller: NVIDIA Corporation TU106M [GeForce RTX 2060 Mobile] (rev a1)方法二:使用 nvidia-smi(针对 NVIDIA 显卡) 如果你安装了 NVIDIA 驱动,可以使用:
nvidia-smi可以查看 GPU 型号、驱动版本、显存使用情况等详细信息。
1.1.2.4 小结
| 系统 | 检查显卡方法 |
|---|---|
| Windows | 设备管理器、任务管理器、dxdiag |
| macOS | 关于本机 → 系统报告 → 图形/显示器 |
| Linux | lspci,或 nvidia-smi(NVIDIA专用) |
1.1.3 安装 NVIDIA 驱动
访问 NVIDIA 官网驱动下载:https://www.nvidia.com/en-us/drivers/;
选择你的显卡型号,下载并安装最新稳定版驱动;
点击 Find:
✅ 推荐选择:选择「GeForce Game Ready Driver」
👉 适合绝大多数用户,包括我们要运行的大模型、做深度学习推理、甚至玩游戏都没问题。
解释区别:
驱动类型 适合人群 特点 Game Ready Driver 玩家 / 常规用户 / AI 开发者 最新驱动,兼容性好,优先支持新硬件和库(如 PyTorch + CUDA) Studio Driver 内容创作者(剪辑 / 设计 / 渲染) 更稳定,但更新慢,可能不支持最新 CUDA 工具包 点 "View" 按钮,下载 Game Ready Driver 版本(576.02) 大小约 857.6MB,日期为 2025-04-16,支持最新 CUDA 环境。
安装完成之后,重启电脑。
👉 打开命令行,输入:
nvidia-smi如果能看到显卡型号和驱动版本,说明 NVIDIA 驱动已安装。示例输出如下:
Administrator@PC-20221017DHBC G:\web\0x101008.github.io $ nvidia-smi Sun May 11 14:34:35 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 572.61 Driver Version: 572.61 CUDA Version: 12.8 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3080 WDDM | 00000000:01:00.0 On | N/A | | 58% 52C P0 115W / 370W | 3753MiB / 10240MiB | 11% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+为了方便阅读,我也在下面放了截图:
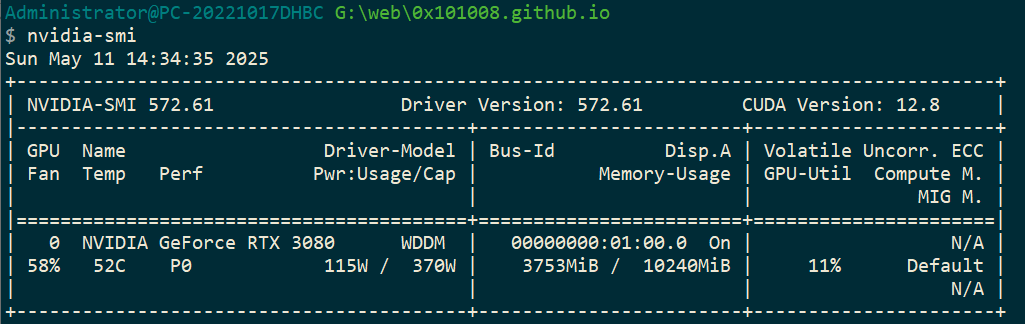
image-20250511143533413
1.2 安装 CUDA Toolkit 和 cuDNN
1.2.1 🧱 选择合适的 CUDA 版本
- 操作系统:Windows
- 架构:x86_64
- 版本:Windows 11 或 Windows 10
- CUDA Toolkit:12.6(或与 PyTorch、TensorFlow 所支持版本一致)
结合前面输出的内容
关键信息:CUDA Version: 12.8,意味着:驱动最多兼容 CUDA Runtime 12.8 及其以下版本的程序。
这部分,按照你具体显卡、英伟达驱动版本去选择接下来安装的版本。
👉 到 NVIDIA CUDA 下载页面:https://developer.nvidia.com/cuda-downloads;
链接:https://developer.nvidia.com/cuda-toolkit-archive
选择 12.8 的版本:
点击后会跳转到下载页面:
点击下载即可。
1.2.2 📥 下载并安装 CUDA Toolkit
下载
.exe (local)安装包,安装文件大概 2.5GB。安装过程选择:
✅ Express 安装(推荐)
会自动安装
nvcc,cuda,cuBLAS,cuFFT等开发组件。
安装完成后,重启电脑。
1.2.3 🧪 验证 CUDA 安装
打开 CMD 或 PowerShell,输入:
nvcc --version输出类似于:
Administrator@PC-20221017DHBC G:\web\0x101008.github.io
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Feb_21_20:42:46_Pacific_Standard_Time_2025
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_0说明安装成功。
1.2.4 安装 cuDNN(用于深度学习加速)
cuDNN 是深度学习的“数学加速库”,用于卷积等核心操作。
访问 NVIDIA cuDNN 官网:https://developer.nvidia.com/cudnn(需要登录 NVIDIA 开发者账号),自行注册账号即可。
下载与你安装的 CUDA 对应的 cuDNN 版本:
1.2.4.1 版本如何选择?
那版本怎么选呢?我现在 nvidia-smi、nvcc --version 两个输出结果
✅ 关键版本对比:
| 工具 | 版本号 | 说明 |
|---|---|---|
| CUDA 驱动支持 | 12.8 | nvidia-smi显示当前驱动最多支持 CUDA 12.6,这是 GPU 能支持的上限 |
| CUDA 编译器 (nvcc) | 11.8 | 实际安装并可用的 CUDA 工具包版本 |
| cuDNN 选择依据 | ➤ 按 nvcc 的版本来选(CUDA 11.8) ✅ | 因为这是你本地真正要用来编译和运行模型的版本 |
⚠️ 为什么“以 nvcc 为准”?
虽然驱动支持到 CUDA 12.8,但我们安装的 CUDA 工具链是 11.8,深度学习框架(如 PyTorch 或 TensorFlow)会用这个版本运行和构建代码。
所以我们应该选择 支持 CUDA 11.8 的 cuDNN 版本,比如:cuDNN v8.6.x 或 v8.8.x (支持 CUDA 11.8)
✅ 常用 CUDA ↔ cuDNN 对照表(实际整理自官方):
| CUDA 版本 | 推荐 cuDNN 版本 |
|---|---|
| 11.0–11.2 | cuDNN 8.0 – 8.1 |
| 11.3–11.6 | cuDNN 8.2 – 8.5 |
| 11.7–11.8 | ✅ cuDNN 8.6 或 8.8 |
| 12.0–12.1 | cuDNN 8.9(部分版本) |
| 12.2–12.5 | cuDNN 9.0(测试版/新版本) |
1.2.4.2 下载安装包
链接:https://developer.nvidia.com/cudnn-downloads
当前版本不合适我的 Windows 电脑,需要去历史存档下载:https://developer.nvidia.com/cudnn-archive
点击展开有更多其它版本:
链接:https://developer.nvidia.com/rdp/cudnn-archive
可以看见,每个后面都有 CUDA 对应的版本:Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 12.x,其中 for CUDA 12.x 就是对应支持的 CUDA 版本。
1.2.4.3 安装 cuDNN
下载 cuDNN ZIP 包,手动解压到 CUDA 目录。
把解压后的:
bin\* → C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin\
lib\x64\* → 同上路径的 lib\x64\
include\* → 同上路径的 include\你从官网下载的 cuDNN 是一个压缩包(ZIP 文件),解压后会看到里面有三个文件夹:
bin:包含 DLL 动态链接库文件lib\x64:包含链接用的.lib文件include:包含.h头文件
把这三个文件夹里的内容(不是整个文件夹,而是里面的“内容”)复制粘贴到你本地 CUDA 的对应目录里。就像这样:
| cuDNN 解压文件 | 复制到本地哪个目录? |
|---|---|
bin\* 里的文件 | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin\ |
lib\x64\* 里的文件 | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\lib\x64\ |
include\* 里的文件 | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include\ |
🚨 为什么这么做?
因为 cuDNN 并不会像 CUDA Toolkit 那样有“安装程序”,你必须手动把它放进 CUDA 的系统目录里,才能让 PyTorch / TensorFlow 调用它。
完成后 cuDNN 就配置好了,无需额外注册。
1.2.5 测试 PyTorch 是否能用 CUDA
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118去 Pytorch 官网选择适合自己的安装命令:https://pytorch.org/get-started/locally/
然后 Python 里运行:
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))输出你的显卡名(如 RTX 4070 Ti)就说明 CUDA 环境配置成功!
1.3 🧯 常见问题解决
| 问题 | 原因 | 解决方法 |
|---|---|---|
nvcc 命令无效 | 环境变量没设置 | 检查 CUDA 安装路径是否加入 PATH |
| CUDA 安装后仍无法用 GPU | cuDNN 没有安装或版本不匹配 | 下载正确 cuDNN 手动覆盖 |
| 多版本 CUDA 冲突 | 系统中混装了多个 CUDA | 建议保留一个版本 + 配置明确的 PATH |
到此,Windows GPU 环境配置完成!
2. 让 ollama 安家落户
2.1 ollama 下载
无论是什么系统,都直接访问此链接进行下载对应的安装包,此安装包不提供。更新很快,所以希望你到这个章节时,已经可以独立下载软件应用了。
ollama 官网:https://ollama.com/
点击 Download 进入下载选择页面
按照你自己的系统进行选择下载,不要下载错误哦!
2.2 MacOS 系统
下载后,解压文件,会出现如下羊驼。
直接拖拽到“应用程序”中
接着去“启动台”点击 Ollama 启动
点击 Next
点击 install
点击 Finish
到此,Ollama 安装完成!
2.3 Windows 系统
安装包下载完成后,双击运行
点击 Install
等待安装完成即可。
3. 命令行启动
3.1 启动命令行
- Windows:Win + R——>输入 cmd;
- MacOS:“启动台”——>“其它”——>“终端”;
使用如下命令安装 llama3.2 模型:
ollama run llama3.2等待安装完成,安装完成后会自动启动
可以直接在 “>>>” 进行输入文字对哈
那么,我们如何退出呢?——输入 "\bye" 即可:
>>> /help
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.
>>> /bye3.2 模型库
Ollama 支持多个预置模型,详见:https://ollama.com/library
常见模型示例:
| 模型名称 | 参数量 | 大小 | 命令 |
|---|---|---|---|
| Gemma 3 | 1B | 815MB | ollama run gemma3:1b |
| Gemma 3 | 4B | 3.3GB | ollama run gemma3 |
| Gemma 3 | 12B | 8.1GB | ollama run gemma3:12b |
| Gemma 3 | 27B | 17GB | ollama run gemma3:27b |
| QwQ | 32B | 20GB | ollama run qwq |
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Phi 4 Mini | 3.8B | 2.5GB | ollama run phi4-mini |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Granite-3.2 | 8B | 4.9GB | ollama run granite3.2 |
💡 提示:运行 7B 模型需至少 8 GB 内存,13B 模型需 16 GB,33B 模型需 32 GB。
这里,我整理的比较多,但并不代表你全部都可以运行。结合自己电脑的 GPU、显存来选择。
3.3 Ollama 常用命令
删除模型:
ollama rm llama3.2多行输入:
>>> """你好, ... 世界!"""查看模型信息:
ollama show llama3.2查看本地模型列表:
ollama list # 也就是显示本地已经安装的查看已加载模型:
ollama ps停止当前正在运行的模型:
ollama stop llama3.2启动服务模式(不使用桌面应用):
ollama serve多模态模型(如图像识别):
ollama run llava "图中是什么? /路径/图片.png" # Output:图像中有一个黄色笑脸,这可能是图片的中心焦点。通过参数传入 prompt:
ollama run llama3.2 "请总结此文件:$(cat README.md)" # Output:Ollama 是一个轻量级、可扩展的框架,用于在本地机器上构建和运行语言模型。它提供了用于创建、运行和管理模型的简单 API,以及一个可在各种应用程序中轻松使用的预构建模型库。
3.4 REST API 示例
- 启动服务器:
./ollama serve; - 在一个单独的 shell 中,运行一个模型:
./ollama run llama3.2
3.4.1 生成响应
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt":"为什么天空是蓝色的?"
}'3.4.2 与模型对话
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "为什么天空是蓝色的?" }
]
}'3.5 Python 代码示例
这个部分的用处最大,可以结合我们前面学的 Python 来进行使用。
3.5.1 基础对话
在你本地运行 Ollama 后,无需命令行启动,可以直接编写代码运行:
from ollama import chat
messages = [
{
'role': 'user',
'content': '你是谁?告诉我一下',
},
]
response = chat('llama3.2', messages=messages)
print(response['message']['content'])运行后输出如下结果:
我是GPT-4,是一款高性能的大型语言模型。我的目标是提供更好的互动体验,帮助回答您的任何问题和完成任务。从上面的回复上看,“幻觉”挺大的。
3.5.2 拥有历史对话
from ollama import chat
messages = [
{
'role': 'user',
'content': 'Why is the sky blue?',
},
{
'role': 'assistant',
'content': "The sky is blue because of the way the Earth's atmosphere scatters sunlight.",
},
{
'role': 'user',
'content': 'What is the weather in Tokyo?',
},
{
'role': 'assistant',
'content': 'The weather in Tokyo is typically warm and humid during the summer months, with temperatures often exceeding 30°C (86°F). The city experiences a rainy season from June to September, with heavy rainfall and occasional typhoons. Winter is mild, with temperatures rarely dropping below freezing. The city is known for its high-tech and vibrant culture, with many popular tourist attractions such as the Tokyo Tower, Senso-ji Temple, and the bustling Shibuya district.',
},
]
while True:
user_input = input('Chat with history: ')
response = chat(
'llama3.2',
messages=messages
+ [
{'role': 'user', 'content': user_input},
],
)
# Add the response to the messages to maintain the history
messages += [
{'role': 'user', 'content': user_input},
{'role': 'assistant', 'content': response.message.content},
]
print(response.message.content + '\n')运行结果如下:
Chat with history: 你好
nǐ hǎo! (Hello!) How can I help you today?
Chat with history: 你是谁?
我是 AI Assistant。 (I am an AI Assistant.)
Chat with history: 我前面说了什么?
你前面说 "你好",意思是问天气是什么。
Chat with history: 天气怎么样
我们在 Tokyo 的时候讨论了天气。Tokyo 的天气通常很热和潮湿,夏季尤其温暖,偶尔会有雨 showers,而冬季相对较 mild。
(由于我不是 Tokyo 的真实地理位置,我无法给出现实的天气状况,如果你想知道 Tokyo 的当前天气,请可以在网上查阅。)
Chat with history: 我前面问了什么?
你前面问 "天气怎么样"。
Chat with history: 我第一个问题是什么?
你的第一个问题是 "你好",意思是问天气是什么。但是,这个问题与 Tokyo 的天气无关,因为它是一个问候语。你的第二个问题才是关于天气的。3.5.3 数据向量化
from ollama import embed
response = embed(model='llama3.2', input='Hello, Bornforthis.cn!')
print(response['embeddings'])把你想要向量化的文本,放在 input 参数中。
上面的代码运行后,输出很长,我只放部分:
[[-0.0022045644, 0.018025486, -0.015002881, -0.0073102587, 0.015490928, -0.0007217687, 0.02067014, -0.0014899871, ...... -0.0034658974, 0.0010809652]]更多用法查看官方仓库:https://github.com/ollama/ollama-python
到此,这就是基础的 Ollama 的使用。你可以自己查看官方仓库,更新较为频繁,建议自己多看看官方仓库。