ChatGLM3-6B本地部署
1. 大模型的选择
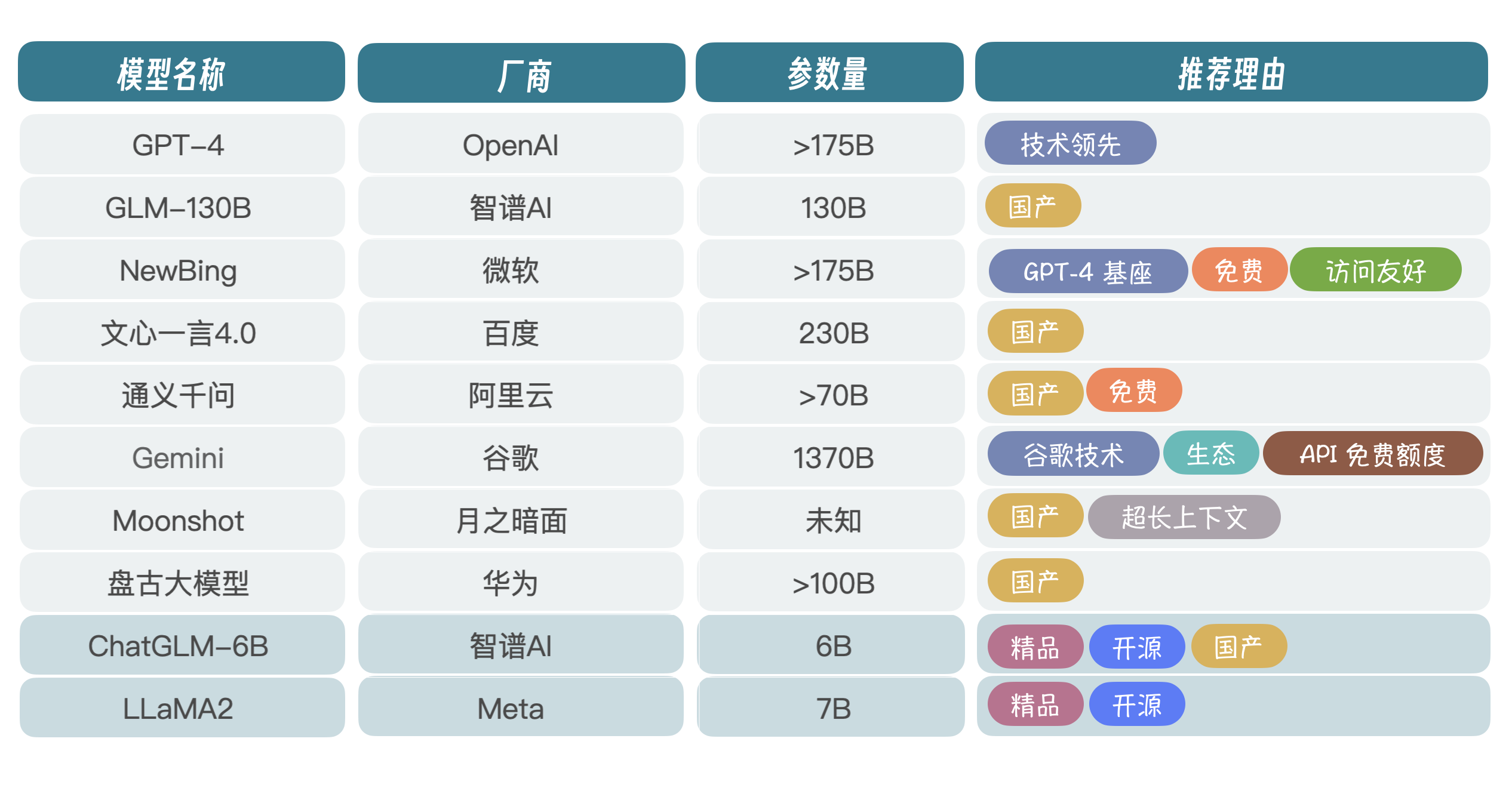
当然,也有不少厂商是基于 LLaMA 爆改的,或者叫套壳,不是真正意义上的自研大模型。
ChatGLM-6B 和 LLaMA2 是目前开源项目比较热的两个,早在 2023 年年初,国内刚兴起大模型热潮时,智谱 AI 就开源了 ChatGLM-6B,当然 130B 也可以拿过来跑,只不过模型太大,需要比较多的显卡,所以很多人就部署 6B 试玩。
从长远看,信创大潮下,国产大模型肯定是首选,企业布局 AI 大模型,要么选择 MaaS 服务,调用大厂大模型 API,要么选择开源大模型,自己微调、部署,为上层应用提供服务。使用 MaaS 服务会面临数据安全问题,所以一般企业会选择私有化部署 + 公有云 MaaS 混合的方式来架构。在国产厂商里面,光从技术角度讲,我认为智谱 AI 是国内大模型研发水平最高的厂商,这也是我选择 ChatGLM-6B 的原因。
还有一点需要考虑,就是 6B 参数规模为 62 亿,单张 3090 显卡就可以进行微调(P-Turing)和推理,对于中小企业而言,简直就是福音。
当然,如果企业预算充足(百万以上),可以尝试 GLM-130B,简称 130B,千亿参数规模,推理能力更强。

下面我们讲讲预算不足的情况下,怎么搞定显卡资源?
2. 如何搞定显卡资源?
玩儿大模型第一步就是要想办法解决计算资源问题,要么 CPU 要么 GPU,当然还有 TPU,不过 TPU 太小众,这里我就不介绍了。我建议你想办法申请 GPU,因为适合 CPU 计算的大模型不多,有些大模型可以在 CPU 上进行推理,但是需要使用低精度轻量化模型,而低精度下模型会失真,效果肯定不行,只适合简单把玩。如果要真正体验并应用到实际项目,必须上 GPU。那我们可以从哪些渠道去购买 GPU 呢?
- 购买二手显卡:无论是个人使用还是企业使用,都可以考虑在网上购买二手 RTX3090 显卡,单卡 24G 显存,8000 块左右,可以用于本地微调、推理。如果想用在产品上,也可以通过云服务做映射,提供简单的推理服务,但是不适合为大规模客户提供服务。
- 淘宝租赁显卡资源:适合个人学习使用,可以按天 / 周 / 月 / 年购买服务,比较灵活,成本也不高。
- 在线 GPU 租赁:比如 autodl、RTX3090-24G,每月大概不到 900 块钱,也很划算。不仅仅可以用来本地测试,还可以用于生产环境推理,如果用在生产环境的话,最好按照实际推理需求,评估每秒推理量(具体方法我会在大模型应用架构部分讲解),搭建高可用推理环境。
- 各个平台免费资源:比如阿里云 PAI 平台、智谱 AI 的开放平台等,对于新人都有一定的免费 GPU 额度,这个方式省钱,但是不推荐,因为有时需要为平台推广拉人,也挺耗时间的。
3. ChatGLM3-6B 部署
ChatGLM-6B 目前已经发展到第 3 代 ChatGLM3-6B,除了中英文推理,还增强了数学、代码等推理能力,我记得一年前的 6B 在代码或者数学方面是比较弱的。根据目前的官方信息,在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 在 10B 以下的基础模型中性能是最强的,除此之外,还具有 8K、32K、128K 等多个长文理解能力版本。下面我们就一步一步来安装部署 ChatGLM3-6B,你也可以在官方文档里找到安装教程。
3.1 准备环境
操作系统推荐 Linux 环境,如 Ubuntu 或者 CentOS。

Python 推荐 3.10~3.11 版本。
Transformers 库推荐 4.36.2 版本。
Torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
注意:
需要提前装好pytorch(Start Locally | PyTorch)根据自己的配置选择对应的选项复制命令运行即可
3.2 克隆代码
git clone https://github.com/THUDM/ChatGLM3
3.3 创建虚拟环境并激活
python3 -m venv .venv
source .venv\bin\activate3.4 安装依赖
注意:要切换成国内 pip 源,比如阿里云,下载会快很多。
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
cd ChatGLM3
pip install -r requirements.txt显示以下内容表明依赖安装成功。
3.4.1 Windows 配置问题
注意
Windows 用户,请直接使用 Wsl + Python 3.11 来实现本地化无痛部署,我已经为你趟过这条泥泞的路~
# 先尝试更新软件包列表:
sudo apt update && sudo apt upgrade -y
# 然后再次尝试:
sudo apt install -y python3.11
# 如果仍然找不到 python3.11,继续尝试下面的方法。
# 1. 确保 software-properties-common 已安装
sudo apt install -y software-properties-common
# 2. 添加 deadsnakes PPA
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt update
# 3. 安装 Python 3.11
sudo apt install -y python3.11
# 4. 检查安装
python3.11 --version
# 安装 python3.11-venv 包
sudo apt install python3.11-venv
python3.11 -m venv .venv- vllm 库问题
因为官方提供的 requirements.txt 是会报错的,因为 vllm 只支持 Linux,不支持 Windows 平台!
解决方法也很简单,直接换系统安装 Linux,把 Windows 系统完全抹掉,这样就可以解决咯!
是不是菊花一紧哈哈哈哈哈,怎么可能。我怎么会为了一个大模型安装 Linux,太麻烦了、成本太高了!
Windows 11 应用商店安装 Linux 系统
安装成功后,使用命令行输入:wsl「进入 Linux 命令界面」
创建虚拟环境:
python3 -m venv .venv激活虚拟环境:
source .venv/bin/activate安装依赖包:
pip install -r requirements.txt遇见 GPU 驱动问题,不讨论具体的 GPU 安装流程(后续补充文章);
在 WSL 中运行以下命令,确认 NVIDIA 驱动正常:
nvidia-smi;如果 nvidia-smi 正常运行,说明 WSL 能正确检测到显卡。
检查 nvcc 是否可用:
nvcc --version如果 nvcc 命令找不到,说明 CUDA 可能没有正确配置。
配置请求源:
检查 WSL 发行版:
cat /etc/os-release;确保你使用的是 Ubuntu 20.04 或 22.04,如果是较老的版本(如 18.04),建议升级。
如果文件不存在或内容不包含
developer.download.nvidia.com,需要手动添加 CUDA 软件源。WSL 需要专门的 CUDA 版本才能使用 GPU 加速,添加 NVIDIA CUDA 源:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pub sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /" sudo apt update然后尝试安装:
sudo apt install cuda-12-6;
安装完成后,配置环境变量:
vim ~/.bashrc,英文输入法下,按下i,末尾添加:export PATH=/usr/local/cuda-12.6/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH按下
esc输入:wq;source ~/.bashrc;
再次检测:
nvcc --version输出版本信息即可。去官网查看自己的 torch 安装命令:https://pytorch.org/get-started/locally/
再次安装依赖即可:
pip install -r requirements.txt
3.4.2 其它问题
- 磁盘空间不足「自行解决」
- Python 版本问题,安装 Python3.11 或其它版本即可解决;
- Windows 安装的 wsl 可以在 Windows 系统应用中点击移动,移动到别的硬盘!
3.5 下载模型
git clone https://huggingface.co/THUDM/chatglm3-6b如果 Huggingface 下载比较慢的话,也可以选择 ModelScope 进行下载。下载完将 chatglm3-6b 文件夹重新命名成 model 并放在 ChatGLM3 文件夹下,这一步非必需,只要放在一个路径下,在下一步提示的文件里,指定好模型文件路径即可。
3.6 命令行模式启动
打开文件 basic_demo/cli_demo.py,修改模型加载路径。
MODEL_PATH = os.environ.get('MODEL_PATH', '../model')执行 python cli_demo.py。

 0
0 0
0 0
0 0
0 0
0